Loading...

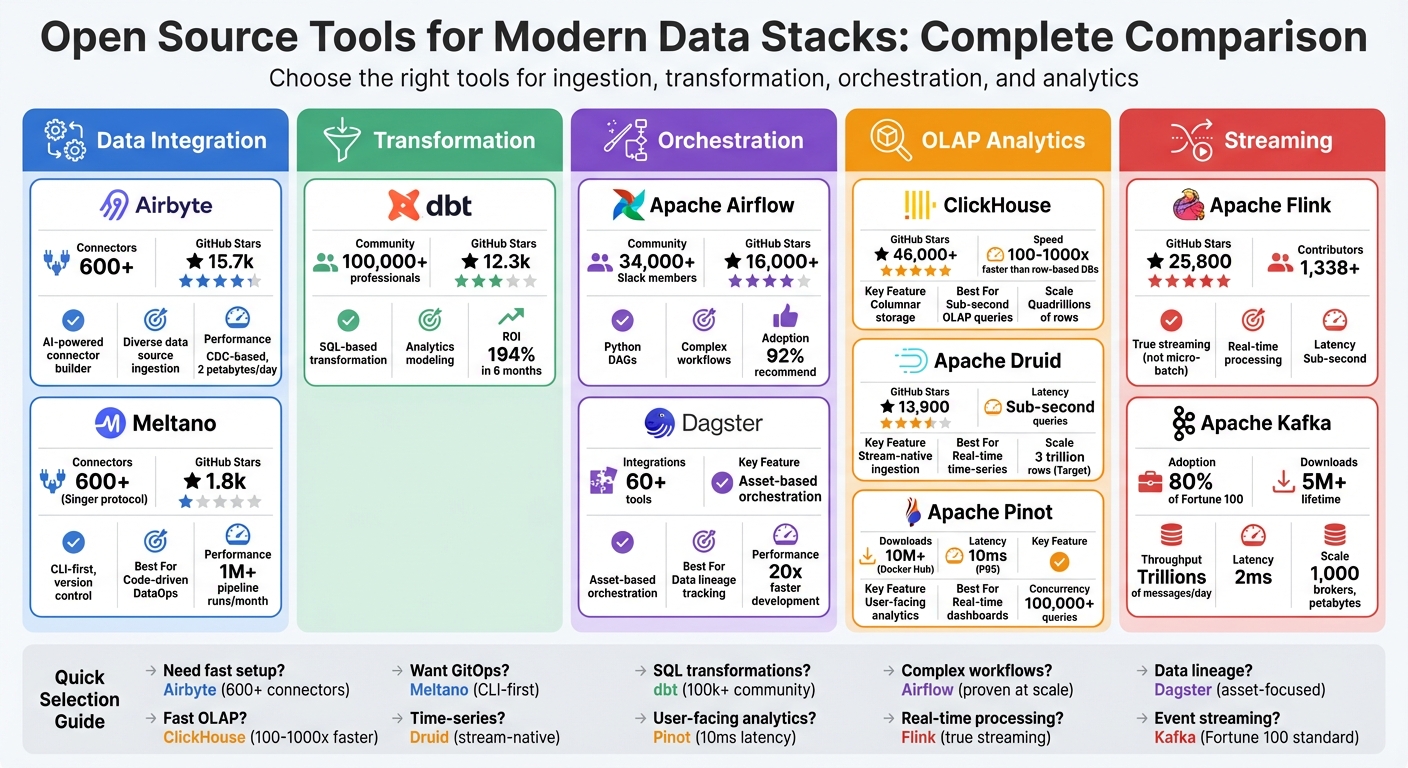
Building a modern data stack is all about choosing the right tools for data ingestion, transformation, orchestration, and analytics. Open-source solutions dominate this space, offering cost savings, flexibility, and active community support. Here's a quick breakdown of the top tools:
Each tool excels in specific areas, from handling massive data volumes to supporting complex workflows. Below is a comparison table summarizing their key strengths and use cases.
| Tool | Focus Area | Key Strengths | Best For |
|---|---|---|---|
| Airbyte | Data Integration | 600+ connectors, AI tools | Ingesting diverse data sources |
| Meltano | DataOps | CLI-first, version control | Code-driven pipeline building |
| dbt | Data Transformation | SQL-based, strong community | Analytics-ready data modeling |
| Apache Airflow | Workflow Orchestration | Python DAGs, ecosystem support | Managing complex workflows |
| Dagster | Orchestration | Asset-based workflows | Data lineage and observability |
| ClickHouse | OLAP Analytics | Sub-second queries, scalability | High-speed analytics |
| Apache Druid | Real-Time Analytics | Time-series optimization | Streaming data exploration |
| Apache Pinot | User-Facing Analytics | Millisecond query latency | Real-time dashboards |
| Apache Flink | Streaming Processing | Low-latency, real-time tasks | Continuous data flows |
| Apache Kafka | Event Streaming | High throughput, fault-tolerant | Streaming pipelines |
This guide breaks down each tool's features, strengths, and ideal use cases to help you build a scalable, cost-efficient data stack.
Open Source Data Stack Tools Comparison: Features, Performance & Community Support
Explore AI Tools on Flaex.ai
Discover the best AI tools for your workflow, curated, reviewed, and ranked.
Browse Directory →
Airbyte is an open-source data integration platform designed to move data from sources like SaaS tools, databases, and APIs into your data warehouse or lake. With over 600 pre-built connectors, it supports everything from widely-used platforms to niche applications, making it a versatile choice for building modern, scalable data pipelines.
"Airbyte is the most complete, future-proof ELT platform in 2026 thanks to its 600+ open-source connectors, AI-assisted connector builder, and flexible self-hosted + SaaS options." - Jim Kutz, Data Analytics Expert
Here’s a closer look at what makes Airbyte stand out in integration, performance, scalability, and community support.
Airbyte simplifies the setup of data pipelines, even for those without extensive technical expertise. Its no-code interface allows users to configure connections through a visual dashboard. For those exploring broader ecosystems, you can browse other AI tool categories to find complementary automation software. If a needed connector isn’t available, the AI-powered Connector Builder can scan API documentation and auto-generate configurations, enabling custom connectors to be created in minutes. Developers can also use the Connector Development Kit (CDK) to build connectors in Python or leverage PyAirbyte, a Python library, to pull data directly into notebooks or scripts.
Airbyte handles data synchronization efficiently using log-based Change Data Capture (CDC) for databases like PostgreSQL and MySQL. This method streams only the changes instead of entire tables, reducing strain on production systems while ensuring near real-time data updates. The platform also supports parallel syncs, which means it can fetch data from multiple sources simultaneously without causing bottlenecks. Impressively, Airbyte processes over 2 petabytes of data daily, showcasing its ability to handle high data volumes.
Built with scalability in mind, Airbyte uses Kubernetes-native scaling, which adjusts processing power automatically based on demand. This approach supports modular scaling, a key feature for modern data architectures. It also offers multi-tenant deployments, allowing teams or business units to work in isolated environments. For added flexibility, the platform supports hybrid deployments, where the control plane operates in Airbyte’s cloud, while the data plane remains on private infrastructure (AWS, GCP, Azure, or on-premises). This setup ensures data sovereignty without compromising ease of management.
Airbyte’s thriving community includes over 20,000 active members, 1,000+ contributors, and has earned more than 16,000 GitHub stars. This active ecosystem drives rapid troubleshooting, connector development, and strong engagement among developers. Users can access support through Slack channels, a Discourse forum, and GitHub discussions. Contributors aiming for "Airbyte Certified" status can follow a "Quality Certification Checklist" to ensure their connectors meet reliability standards. While self-hosting Airbyte is free, its Airbyte Cloud service uses a capacity-based pricing model, charging based on compute credits rather than rows or connection fees.
Building on the integration framework offered by tools like Airbyte, Meltano provides a command-line interface (CLI)-driven solution that embraces an "Everything-as-Code" philosophy.
Meltano is an open-source DataOps platform that treats data pipelines as software projects, emphasizing a CLI-first, code-centric approach. Based on the Singer specification, it connects users to over 600 pre-built connectors via the Meltano Hub, covering databases, SaaS APIs, and file formats. Originally developed at GitLab, Meltano now facilitates over 1,000,000 pipeline runs every month.
"I've been moving >1TB/day with Meltano for over a year now at a negligible cost... It saves us at least $1M/yr and makes my job easy." – Quinn Batten, Senior Analytics Engineer
Meltano simplifies the integration process by unifying extractors, loaders, dbt transformations, orchestrators, and data quality tools under a single CLI. All configurations are stored in a meltano.yml file, which can be version-controlled in Git, enabling code reviews and seamless CI/CD workflows. For custom needs, the Meltano SDK makes it easy to build connectors for specialized or internal APIs, reducing development time from days to just hours. Additionally, it supports inline data mapping and automated state management, allowing incremental replication to resume without interruptions.
Meltano ensures efficient data transfers by using key-based and log-based (CDC) incremental replication, which only syncs changed data. The platform automatically adjusts to schema changes, enhancing pipeline reliability and security. Whether syncing 500 rows or 5,000,000, Meltano delivers consistent performance. Stéphane Burwash from Potloc noted:
"Incredible tool – whether you need to sync 500 or 5,000,000 rows, Meltano will perform the task with ease."
Comprehensive pipeline logs and alerting systems provide full visibility, enabling teams to quickly pinpoint and resolve issues.
Meltano’s GitOps integration allows pipeline configurations to be version-controlled, supporting rollbacks and collaborative workflows. It works seamlessly with orchestrators like Apache Airflow and Dagster, which help manage task scheduling and parallel execution as data needs grow. Its CLI-first design supports cloud-agnostic deployments on Kubernetes and Docker, offering flexibility to run workloads wherever they’re needed. With an MIT license, Meltano is free to use regardless of data volume - you only pay for the infrastructure you operate. As Josh Lloyd, Senior Data Engineer at Acquia, shared:
"The time-to-value with Meltano is unbelievable! I've even created brand new connectors in just a few hours rather than days."
Meltano boasts a vibrant community of over 5,500 Slack members who actively share tips and best practices. Its open-source model encourages contributions, while the Meltano SDK and community support make it easier for teams to create and maintain custom connectors. Gary James from Beauty Pie highlighted:
"Meltano's SDK and community support has given us back hours in creating and maintaining custom connectors for various platforms."
The platform’s acquisition by Matatika in early 2024 signals ongoing investment in its open-source capabilities. With no volume-based pricing and full control over its code, Meltano remains a budget-friendly choice for teams looking to build modern data stacks without being tied to a specific vendor.
Once data is ingested using tools like Airbyte or Meltano, the next step is transformation. This is where dbt (data build tool) shines. dbt takes raw data stored in a warehouse and transforms it into analytics-ready datasets using straightforward SQL select statements. It simplifies data modeling by automating tasks like dropping tables, managing schema changes, and ensuring proper execution order. Beyond that, dbt incorporates software engineering practices into analytics workflows, offering features like version control via Git, automated testing, modular design, CI/CD pipelines, and built-in documentation. With a global community of over 100,000 data professionals and more than 60,000 teams using dbt to process billions of transformations, it has become the go-to tool for SQL-based data transformation.
dbt works seamlessly with major cloud data warehouses such as Snowflake, BigQuery, Databricks, and Redshift. As a "Trusted Adapter" for Snowflake, dbt undergoes rigorous testing to ensure reliability. While data ingestion platforms handle the extraction and loading, dbt focuses exclusively on transforming the raw data into actionable insights. The tool also integrates with development environments through a free VS Code extension, powered by its Fusion engine, which offers features like live error detection and lineage visualization. These capabilities make dbt a powerful and efficient solution for data transformation.
The introduction of the Fusion engine significantly enhances dbt's performance by reducing parse times and improving developer responsiveness. Unlike older ETL tools that transform data before loading, dbt leverages the computing power of your data warehouse to execute transformations directly and efficiently. According to Forrester Research, organizations using dbt have reported a 194% ROI within six months and workflows that are up to 30 times faster thanks to automation. Matt Luizzi, Senior Director of Analytics at WHOOP, highlighted the value of accurate data:
"Access to accurate data is critical, it allows us to improve the customer experience and increase retention, lifetime value, and profitability."
dbt's modular design makes it easy to scale as data requirements grow. Reusable packages help teams manage increasingly complex logic, while Git-based version control enables collaborative workflows, code reviews, and rollbacks. The dbt Semantic Layer further enhances scalability by creating a unified source of truth for business metrics across the organization. Kelly Wolinetz, Senior Data Engineer at M1 Finance, shared:
"For our business needs, our investment in AI and dbt Semantic Layer has been worth it."
With its ability to handle billions of transformations, dbt has proven its scalability for teams of all sizes.
dbt boasts an active and supportive community, with over 12,300 stars on GitHub and a Slack group of 34,000+ members. It also enjoys a 4.8/5 rating on G2, with a 97% customer satisfaction score. The platform offers dbt Core as a free, open-source tool under the Apache 2.0 license, while dbt Cloud provides a free tier for small teams and advanced options for enterprises needing extra security and support. Recognized as a "Leader" by Snowflake and Databricks, dbt continues to set the benchmark for modern data transformation.

Once dbt takes care of data transformations, the next step is to orchestrate the entire pipeline. This is where Apache Airflow comes in, a widely-used orchestration tool in modern data workflows. Apache Airflow has become the go-to solution for managing data pipelines through Directed Acyclic Graphs (DAGs). Released under the Apache 2.0 license, it allows you to define workflows using pure Python, making it straightforward to create dynamic pipelines with familiar Python features like loops and date/time functions. With over 16,000 stars on GitHub and contributions from more than 1,000 developers, Airflow is trusted by major companies like PayPal, Twitter, Google, and Square. According to the 2025 Airflow Survey, which gathered insights from 5,818 respondents across 122 countries, 92% of users would recommend it, and 95% rely on it to boost operational efficiency.
Airflow's modular design enables seamless integration with third-party tools via provider packages, which are updated independently of the core platform. These packages cover a range of tools, including Airbyte, dbt Cloud, Snowflake, Databricks, AWS, Google Cloud (GCP), Microsoft Azure, Apache Kafka, and Apache Spark. The Astronomer Cosmos plugin further bridges the gap between transformation and orchestration by allowing dbt projects to run directly as Airflow DAGs. With the release of Airflow 3.x, the new Task SDK introduced a stable interface for writing DAGs, ensuring compatibility with future updates while decoupling them from the internal scheduler and API server. These features make Airflow a highly flexible option for managing workflows.
Airflow is best suited for scheduled batch processes rather than real-time or event-driven tasks. Recent updates have brought significant performance gains. For instance, Airflow 3.1.0, launched on September 25, 2025, introduced specialized workflows for AI/ML pipeline development. Machine learning and AI now account for 28% of Airflow's use cases, showing a 24% year-over-year increase in adoption by late 2024. However, handling high volumes of tasks can lead to latency in the task scheduler, particularly when many DAGs are running at the same time.
Airflow's design allows it to scale effectively, using a message queue to coordinate an unlimited number of workers. Its official Helm Chart simplifies deployment on Kubernetes, leveraging container orchestration for nearly linear scalability. Executors like Kubernetes and Celery further enhance scalability by enabling parallel task execution across multiple nodes. However, to maintain smooth operations, it's essential to stagger DAG schedules when running multiple pipelines concurrently. For organizations looking to reduce the operational overhead of managing Airflow at scale, managed services such as Astronomer, Google Cloud Composer, or Amazon Managed Workflows for Apache Airflow (MWAA) offer convenient alternatives.
Apache Airflow benefits from one of the largest and most active communities in data orchestration, with over 34,000 members on its Slack channel. Its extensive documentation and wide range of custom GPTs and plugins make it easier to find solutions and follow best practices. However, 46% of organizations report that issues with Airflow can disrupt their entire operation, highlighting the need for proper setup and monitoring. For teams navigating these complexities, an AI project advisor can provide tailored recommendations for tool selection and architecture. The release of airflowctl 0.1.0 in October 2025 introduced a secure, API-driven command-line tool that eliminates the need for direct access to the metadata database. While Airflow itself is free, managed services like Astronomer offer pay-as-you-go pricing, starting at $0.35 per hour, for those seeking a simpler setup.
While Apache Airflow emphasizes task-based workflows, Dagster offers a fresh perspective by treating data assets as first-class entities. This asset-focused design provides a clear, declarative map of dependencies across your data stack, making it easier to understand how data flows through your pipelines. Unlike traditional task-focused tools, Dagster's approach complements tools like dbt, which centers on data transformation, and Airflow, known for orchestration. Since its release as open source, Dagster has gained popularity among teams looking for modern solutions that prioritize data lineage and observability. Steven Ayers, Principal Engineer at Ayersio Services Limited, highlights this advantage:
"The asset-based approach of orchestration massively reduces cognitive load when debugging issues because of how it aligns with data lineage".
Dagster's asset-centric model integrates smoothly with over 60 major tools. Using its Software-Defined Assets feature, you can define data objects directly in code, automatically tracking relationships between tools in your stack. The Dagster Pipes functionality streams logs and metadata, offering deep visibility into jobs running on platforms like Spark or Snowflake. For teams transitioning from legacy systems, Dagster includes tools to migrate Airflow DAGs into its asset-based workflows.
Dagster is designed to efficiently manage dependencies, supporting features like incremental runs and partitions to minimize unnecessary processing. Its use of strong typing ensures pipeline logic is validated before execution, helping catch errors early. Real-time health metrics provide insights into asset freshness and performance, allowing teams to quickly identify and address bottlenecks. These metrics work seamlessly with tools like dbt and Airflow, enhancing the overall performance of your data stack. Gu Xie, Head of Data Engineering, shares:
"Dagster has been instrumental in increasing our development velocity to deliver insights at 20x the velocity compared to the past. From Idea inception to Insight is down to 2 days vs 6+ months before".
Dagster is built to scale, offering parallel execution through Kubernetes or Celery executors. Its multi-tenant architecture ensures team isolation, while its modular design supports the reuse of components as your data stack grows in complexity. Features like backfills and replays allow teams to recompute specific parts of a pipeline without manual intervention, which is especially helpful when working with large-scale historical data. This scalability ensures Dagster can handle the evolving demands of modern data workflows.
Dagster provides extensive onboarding resources, including Dagster University, which offers interactive courses and hands-on tutorials. Its active Slack community provides real-time support, while GitHub Discussions enable long-term collaboration. The open-source version is free, but teams looking for additional features can opt for Dagster Plus, which includes managed services, hosted instances, SSO, RBAC, and enterprise-level support. These resources and options make Dagster a flexible and scalable choice for teams building a modern data stack.
ClickHouse is an open-source columnar database built for real-time analytics, boasting query speeds that are 100× to 1,000× faster than traditional row-based databases. Thanks to its vectorized engine and columnar storage, it delivers sub-second analytics even when working with billions of rows. It scales effortlessly - maximizing CPU usage on a single machine (vertical scaling) or spreading workloads across hundreds of nodes (horizontal scaling). With over 46,000 stars on GitHub and contributions from 2,736 developers, ClickHouse has become a go-to solution for modern data infrastructure.
ClickHouse seamlessly integrates with existing data ecosystems, supporting over 70 file formats, including Parquet, Apache Iceberg, and Delta Lake. Its ClickPipes feature simplifies ETL and Change Data Capture (CDC) processes, enabling real-time sync with databases like PostgreSQL and MySQL - no middleware required. For quick prototyping, the clickhouse-local binary, weighing just ~100MB, lets users run the full SQL engine locally, making it cost-efficient for unit testing. These features make it easy to transition from data ingestion to analysis without friction.
The performance gains with ClickHouse are striking. Companies report 10× to 20× faster query speeds and significant cost savings when switching from platforms like AWS Redshift or Apache Pinot. Its sparse primary index uses minimal memory - just a few megabytes per terabyte of data - while scaling to handle quadrillions of rows with fast data pruning. In benchmarks, ClickHouse consistently outpaces other cloud data warehouses, delivering 2× to 10× faster analytics and achieving up to 4× lower total costs compared to Snowflake.
ClickHouse shines in handling large-scale workloads across various industries. For instance:
Its cloud-native architecture separates storage and compute, with stateless compute nodes accessing object storage like S3. This design allows instant horizontal scaling and workload isolation. On ClickHouse Cloud, a single node can manage over 1,000 queries per second, while columnar storage compresses data by 10× to 20×, cutting storage expenses.
ClickHouse thrives on its vibrant community, with over 100,000 developers actively engaging on platforms like Slack, Telegram, and GitHub Discussions. The project follows a rapid monthly release cycle, sharing updates through community webinars. Comprehensive documentation and engineering blogs provide valuable guidance for users. While the open-source version is free, teams looking for managed services can opt for ClickHouse Cloud, starting at $50 per month.
"Using ClickHouse resulted into a lot of performance benefits for us with huge cost savings for the org" - Lyft
Apache Druid is an open-source analytics database designed for real-time data ingestion and interactive queries at scale. Unlike traditional databases that rely on batch processing, Druid connects directly to streaming platforms like Apache Kafka and Amazon Kinesis without needing external connectors. This means data can be queried immediately, with sub-second latencies, even for datasets ranging from terabytes to petabytes. With 13,900 GitHub stars and contributions from 645 developers - including teams at Apple, Netflix, and Alibaba - Druid has earned its place as a reliable solution for high-concurrency analytical applications.
Druid's stream-native architecture makes it easy to integrate with streaming data sources. It connects directly to Kafka and Kinesis streams with exactly-once processing guarantees, eliminating the need for middleware. The introduction of the Multi-Stage Query (MSQ) engine adds SQL-based ingestion capabilities, allowing users to perform complex transformations and joins during the data loading process using familiar SQL commands like INSERT and REPLACE. This feature simplifies data pipelines by enabling seamless integration of streaming clickstream data with batch-loaded catalogs during ingestion.
"Druid is like a brother to Kafka and Flink. It too is stream-native. In fact, there is no connector between Kafka and Druid as it connects directly into Kafka topics." - David Wang, Developer Advocate, Imply.io
This streamlined integration is key to Druid's ability to handle high-speed data ingestion and deliver rapid query performance.
Druid employs columnar storage, compressed bitmap indexes (Roaring or CONCISE), and time-based partitioning to process millions of records per second while maintaining query latencies of less than a second to just a few seconds. Its rollup feature pre-aggregates data during ingestion, cutting storage requirements by 10× to 100× and improving query speeds. As an example, Confluent uses Druid to power its Health+ dashboard, which ingests 5 million events per second from Kafka and handles 350 concurrent queries per second, providing users with real-time insights into their environments. These capabilities make Druid a strong choice for user-facing analytical applications where high concurrency and fast response times are critical.
And thanks to its architecture, Druid can easily scale to accommodate growing data and user demands.
Druid's distributed architecture separates ingestion, querying, and coordination into independent components that scale individually. It stores data in deep storage systems like S3, HDFS, or GCS, ensuring durability and making it simple to expand the cluster. When new nodes are added, they pull data from shared storage, and the system automatically rebalances data in the background without downtime. For instance, in January 2026, Target reported using Druid to process 3 trillion rows from 3,500 data sources, enabling real-time analysis of inventory across its supply chain. Druid deployments often range from tens to hundreds of servers, handling anywhere from 100 to 100,000 queries per second.
The Apache Druid community is highly active, offering support through various channels. Slack is the go-to platform for immediate help, although the 90-day message retention limit is addressed by tools like Linen and Struct, which archive and make past discussions searchable. The project’s development is ongoing, with version 36.0.0 released on February 9, 2026. Comprehensive documentation is available, covering everything from quickstarts and security best practices to SQL API references and a "Druid Data Cookbook" for advanced transformations. For teams needing enterprise-grade support, several providers - including Imply, Cloudera, Rill Data, Deep.BI, and Datumo - offer commercial services.
Apache Pinot stands out as a high-performance analytics database tailored for delivering real-time, user-focused insights. Designed as an open-source solution, Pinot was initially developed at LinkedIn to power features like "Who Viewed My Profile" and later adopted by Uber. Its popularity is evident, with over 10 million downloads on Docker Hub. While traditional OLAP tools cater to internal dashboards, Pinot specializes in providing personalized, real-time analytics directly to end-users, achieving query latencies as low as 10 milliseconds at the 95th percentile.
Pinot integrates seamlessly with streaming platforms like Kafka, Pulsar, and Kinesis, enabling sub-second querying capabilities. It supports standard SQL queries and works with widely-used BI tools. Its architecture is designed for flexibility, with data divided into real-time tables (for streaming data) and offline tables (for batch data). These can be combined into a single logical table, allowing unified queries across both historical and fresh datasets. This setup simplifies handling high-velocity event streams and large-scale batch imports, eliminating the need for complex middleware.
Pinot's performance is powered by its columnar storage, advanced indexing techniques, and distributed design, which ensure high concurrency. It handles over 100,000 concurrent queries while maintaining P90 latencies in the tens of milliseconds, even with petabyte-scale datasets. Features like StarTree indexing for pre-aggregation, Bloom filters, and geospatial indexes ensure sub-second query performance, even for massive aggregation tasks. Uber leverages Pinot for its Restaurant Manager application in UberEats, enabling sub-second aggregation queries over fresh financial data in their internal ledger. Additionally, Pinot supports upserts, ensuring only the latest record values are displayed - an essential feature for real-time financial tracking.
"Pinot enables us to execute sub-second, petabyte-scale aggregation queries over fresh financial events in our internal ledger. We chose Pinot because of its rich feature set and scalability." - Peter Bakkum, Uber
Pinot's distributed architecture is designed for flexibility, with separate node types: Brokers handle query routing, Servers store data segments, and Controllers manage the cluster. This separation allows operators to independently scale query volume, complexity, and data size. Data is sharded into segments and replicated across nodes, ensuring high availability and fault tolerance. At LinkedIn, Pinot supports over 50 user-facing products, handling millions of events per second while delivering millisecond-latency queries. Webex reported a 10× reduction in storage footprint and a cluster size reduction of 500 nodes, all while maintaining sub-second query latencies. Pinot also integrates with modern orchestration and transformation tools, using Apache Helix and ZooKeeper to automate cluster management, state transitions, and resource allocation as the system grows.
As a top-level Apache project, Pinot benefits from a vibrant open-source community, with approximately 1,744 contributors and a software value estimated at $48 million. The project provides extensive documentation, covering everything from quickstart guides to advanced indexing techniques. Community support is readily available through Slack and GitHub. Regular updates introduce features like federated analytics with Delta Lake integration and zero-disk architecture, enhancing scalability and reducing costs.

In today’s data landscape, where low latency and real-time processing are non-negotiable, Apache Flink stands out as a streaming-first engine built to handle continuous data flows. Unlike systems that process data in micro-batches, Flink processes events as they arrive, one by one, ensuring a smooth, real-time experience. While its core focus is streaming, it can also handle batch jobs, treating them as a secondary use case. This approach enables sub-second latency and advanced capabilities for managing event time and out-of-order data, making it a go-to choice for tasks like real-time fraud detection and instant alerts.
Flink integrates effortlessly with key components of the modern data stack, including Apache Kafka, Amazon Kinesis, and Elasticsearch. It provides a unified SQL interface and a DataStream API, which ensures consistent results whether the data source is batch or streaming. For real-time synchronization between transactional databases and analytics platforms, Flink offers Change Data Capture (CDC) connectors that allow users to design no-code workflows in YAML. Additionally, the Flink Kubernetes Operator 1.14.0, introduced in February 2026, simplifies production tasks like Blue/Green deployments, making it easier to manage and scale applications.
Flink achieves a balance of high throughput and low latency through its in-memory computing and pipelined execution engine. Its stateful computation model keeps data and computation close together, either in-memory or on disk, which significantly enhances performance. The platform ensures exactly-once state consistency with lightweight checkpointing, allowing it to recover from failures without data loss or duplication. With more than 20 transformations available in its DataStream API, Flink can handle massive workloads, scaling to thousands of cores and managing terabytes of state.
Flink’s distributed architecture allows it to scale effortlessly for even the most demanding workloads. By breaking applications into thousands of parallel tasks across a cluster, Flink efficiently uses CPU, memory, disk, and network resources. It supports large states - up to several terabytes - through incremental checkpointing, which snapshots only changes since the last checkpoint, reducing latency during processing. Operators can also use savepoints to capture consistent state snapshots, enabling applications to restart with different parallelism levels without losing data. Production environments have demonstrated Flink’s ability to handle trillions of events daily.
Apache Flink benefits from a highly active and engaged community. As of February 2026, it has garnered 25,800 stars and 13,900 forks on GitHub, supported by over 1,338 contributors and 119 committers. The release of Flink 2.2.0 in December 2025 brought new features, including a revamped state backend and enhanced Kubernetes-native operations. The community also organizes the annual "Flink Forward" conference and maintains active mailing lists for developer discussions and support. Licensed under Apache License 2.0, Flink remains fully open-source, with extensive documentation ranging from beginner guides to advanced tutorials on state management.

Apache Kafka plays a central role in modern data ecosystems, delivering reliable, real-time data streaming. Acting as a distributed event store, Kafka connects data sources to destinations seamlessly. It's no surprise that over 80% of Fortune 100 companies depend on Kafka for their critical data workflows. With more than 5 million lifetime downloads, Kafka processes trillions of messages daily, managing petabyte-scale data with an impressive 2ms latency. As one of the top five active projects under the Apache Software Foundation, Kafka has become the go-to solution for organizations needing continuous data streaming between systems.
Kafka Connect simplifies integration with a wide range of event sources and destinations, such as Postgres, JMS, Elasticsearch, and AWS S3, eliminating the hassle of writing custom integration code. Developers can also leverage client libraries for various programming languages, making it easier to process data streams in their language of choice. Kafka acts as a centralized hub, enabling a "connect to almost anything" architecture that streamlines complex data workflows. With built-in support for joins, aggregations, and transformations, Kafka integrates smoothly into analytical workflows, offering event-time and exactly-once processing. This combination of flexibility and performance ensures reliable high throughput and low latency.
Kafka's performance is powered by features like zero-copy I/O, batching, and its append-only log structure, which ensures consistent results even at scale. In recent tests using Kafka 3.7.0, transactional producers achieved 76,000 messages per second with 10 partitions and 1KB messages. By optimizing producer settings - such as increasing batch.size to 128KB and setting linger.ms to 20ms - throughput rose to 135,000 messages per second, effectively doubling performance. Netflix provides a real-world example, using Kafka clusters to handle over 700 billion events daily, equating to roughly 1 petabyte of data routed to systems like S3 or Elasticsearch as of March 2025.
Kafka’s scalability is another standout feature, with the ability to partition topics across thousands of brokers. This allows clusters to scale up to 1,000 brokers while managing petabytes of data. Its architecture separates producers and consumers, enabling parallel processing without bottlenecks - producers don’t need to wait for consumers. Read-side throughput scales linearly until the number of consumers matches the number of partitions, making proper partitioning essential for maximum efficiency. Kafka also supports multi-zone or multi-region setups, ensuring reliability and uptime for critical applications. Unlike traditional message queues, Kafka retains data for a configurable period, storing it safely in a fault-tolerant cluster.
As one of the most active Apache Software Foundation projects, Kafka benefits from a robust community. Developers have access to a wide range of tools, thorough documentation, and global meetups. Popular community tools include ksqlDB for SQL-based stream processing and Redpanda Console for UI management. Kafka also provides five core APIs - Admin, Producer, Consumer, Streams, and Connect - offering developers flexibility in how they interact with the platform. With plentiful online training resources and active forums, developers can easily find guidance for everything from setting up Kafka to managing complex clusters.
Selecting the right tools for building a modern data stack is all about understanding your specific data needs and how each tool fits into your workflow. Here's a breakdown of key tools, highlighting their strengths and limitations.
Airbyte stands out for its ease of integration, boasting over 600 pre-built connectors and automated schema evolution. This makes it a strong contender for quick and efficient data ingestion. On the other hand, Apache Airflow, while offering an extensive integration ecosystem, demands significant operational effort to maintain. As Hugo Lu, CEO of Orchestra, puts it:
"Airflow is difficult and time consuming to build-on and maintain"
Dagster takes a modern, asset-focused approach, streamlining coordination with tools like dbt and ingestion platforms. For real-time data processing, Apache Flink and Apache Kafka shine, delivering high streaming performance. Kafka, in particular, serves as a backbone for event-driven architectures.
When it comes to OLAP (Online Analytical Processing), ClickHouse is a powerhouse. It supports Yandex Metrica's multi-petabyte deployment, handling over 20 billion events daily with sub-second query response times. Meanwhile, Apache Pinot excels in ultra-low latency analytics for user-facing applications, and Apache Druid specializes in time-series data exploration. For teams seeking modularity and Git-native workflows, Meltano offers a moderate setup complexity while leveraging the Singer protocol.
Here’s a quick comparison of these tools across key metrics like integration ease, performance, scalability, and community support:
| Tool | Integration Ease | Performance | Scalability | Community Support | Key Weakness |
|---|---|---|---|---|---|
| Airbyte | High (600+ connectors) | Moderate (CDC-based) | High (Horizontal) | High (15.7k GitHub stars) | Requires infrastructure management |
| Meltano | Moderate | Moderate | Moderate | Moderate (1.8k stars) | CLI-centric with limited ecosystem |
| dbt | High (SQL-based) | Low (Batch-focused) | High (Warehouse-led) | Very High (100k+ members) | Not real-time optimized |
| Apache Airflow | Low (Python/DAGs) | Moderate | High | Very High (5,818 survey responses) | High operational overhead |
| Dagster | Moderate | Moderate | High | High | Newer, smaller community |
| ClickHouse | Moderate | Ultra-High (OLAP) | High (Petabyte) | High (36.9k stars, 570 commits/week) | Complex setup |
| Apache Druid | Low | High (Time-series) | High | Moderate | Optimized for time-series over JOINs |
| Apache Pinot | Low | Ultra-High (User-facing) | High | Moderate | Designed for aggregations over JOINs |
| Apache Flink | Low | Ultra-High (Streaming) | High | High | Steep learning curve |
| Apache Kafka | Moderate | Ultra-High (Streaming) | High | Very High | Needs precise partitioning |
Choosing the right tool depends heavily on your workflow. For lean teams, serverless solutions like Airbyte Cloud can help minimize maintenance costs. If your data processes rely on complex JOIN operations, ClickHouse is a better fit than Pinot or Druid. However, keep in mind that while open-source tools eliminate licensing fees, they often require significant engineering resources. For instance, three engineers dedicating 40% of their time to managing infrastructure could cost between $200,000 and $300,000 annually.
Creating a modern data stack means navigating a sea of tools designed for everything from real-time processing to batch workflows. Flaex AI simplifies this process by organizing over 1,500 tools into categories like Business Intelligence, ETL/ELT, Warehouse/Lake, and Data Quality/Governance. This structure helps you quickly pinpoint the right tools for each layer of your stack.
The platform includes an "Open Source / Self-hosted" filter, allowing you to focus on transparent, vendor lock-in-free tools like Metabase, Superset, and PostHog. You can also refine searches using multiple criteria, such as pricing models (Free, Freemium, or Paid) and capability tags like #OpenSource, #NoCode, #API, and #WorkflowBuilder. This makes it easier to find tools that align with both your budget and technical needs.
AI-driven insights further simplify the process by addressing common integration challenges. These built-in agents compare tools based on features, project maturity (e.g., Promising, Mature, or Legacy), and activity metrics like commits and monthly updates. Whether you're focusing on essential layers like ingestion, transformation, and storage or aiming to decouple compute and storage for scalability, the platform’s recommendations guide you toward tools that integrate seamlessly via APIs.
When it comes to workflow planning, the platform offers detailed tool profiles that highlight integration capabilities, performance, and scalability. For instance, it helps you decide whether to use ClickHouse for complex JOINs or opt for Pinot or Druid for time-series analytics. This level of detail ensures you choose tools that match your workload requirements.
For teams transitioning from monolithic, on-premise systems to modular, cloud-native stacks, Flaex AI provides a roadmap. It helps assess your current setup, define requirements, and ensure smooth interoperability across tools. Adding to this, the community layer allows you to explore shared stacks, gather feedback, and learn from others’ experiences, offering a collaborative edge to your stack-building journey.
Building a modern data stack with open-source tools requires aligning the right technologies with your specific workload needs. For general data ingestion, Airbyte stands out with its impressive library of over 600 connectors. Meanwhile, dbt has solidified its position as the go-to tool for SQL transformations, backed by a thriving community of about 34,000 members. For real-time analytics requiring lightning-fast processing, ClickHouse handles billions of rows effortlessly. And when it comes to complex orchestration, Apache Airflow remains a leader, though tools like Dagster are gaining traction for their improved local testing capabilities.
Cost is a critical factor. For example, a Series B company with 150 employees managed to cut its annual data expenses from $127,000 to $31,000 by swapping out five commercial tools for open-source alternatives like Airbyte and dbt Core. However, as Tinybird aptly points out:
"The uncomfortable truth: open source doesn't eliminate cost - it shifts it from licensing to operations".
Running an open-source analytics setup isn’t free. With three engineers dedicating 40% of their time, operational costs can range from $200,000 to $300,000 annually.
But the benefits of open source go beyond just cost. Transparency allows you to evaluate tools without falling for marketing fluff. Flexibility ensures these tools can integrate seamlessly into your internal systems, and vendor independence helps you avoid being locked into proprietary platforms. In industries with strict regulations or privacy laws, self-hosted open-source solutions might even be your only option.
To get started, focus on the foundational layers first - reliable ingestion and storage - before tackling more advanced needs like observability or governance. For table management, Apache Iceberg ensures compatibility across tools like Spark, Trino, and Flink. If you’re working with smaller datasets (up to a few hundred gigabytes), DuckDB can simplify operations by running in-process, eliminating the need for dedicated infrastructure. By taking an incremental approach, prioritizing integration testing, and keeping a close eye on costs, you can build a data stack that’s efficient and ready for the future.